Data Governance vs Data Management: 7 Differentiating Factors
The Apono Team
January 29, 2026

When data programs fail, they usually fail in two very different ways. Weak data governance shows up as overexposed databases, long-lived credentials, and access that quietly expands far beyond intent, often until it’s exploited. Weak data management really breaks trust from the inside out with stale or inconsistent data, pipelines that stall under their own complexity, and bottlenecks that slow decision-making. These are distinct failure modes with different root causes, yet many organizations still blur the line between governance and management.
That confusion is becoming harder to justify. GitGuardian’s 2025 State of Secrets Sprawl report found 23.77 million new secrets leaked on GitHub in 2024, a 25% year-over-year increase. This is a signal of just how widespread uncontrolled access has become across modern engineering environments.
Data use is across cloud storage, databases, analytics platforms, and internal services, and leaders can’t afford fuzzy definitions or shared ownership gaps. Understanding the difference between data governance vs data management (and how to connect the two) is crucial for keeping your sensitive data usable and defensible.
What is data governance?
Data governance is the framework of policies, rules, and controls that determine who can access data, under what conditions, and how you monitor, enforce, and scale automated access control. It defines ownership, accountability, and acceptable use across an organization’s data estate. Here it’s about security, privacy, and risk reduction, while aligning with regulatory and assurance requirements such as SOC 2, GDPR, and HIPAA.
Crucially, data governance is about decision-making and accountability, not technology alone. Tools can help enforce policies, but governance answers higher-order questions like, who is responsible for this dataset? Who approves access, and for how long? What constitutes appropriate use?
Modern governance programs that focus only on human users are incomplete because non-human identities, such as service accounts, pipelines, applications, and agents, often hold the broadest and most persistent access.
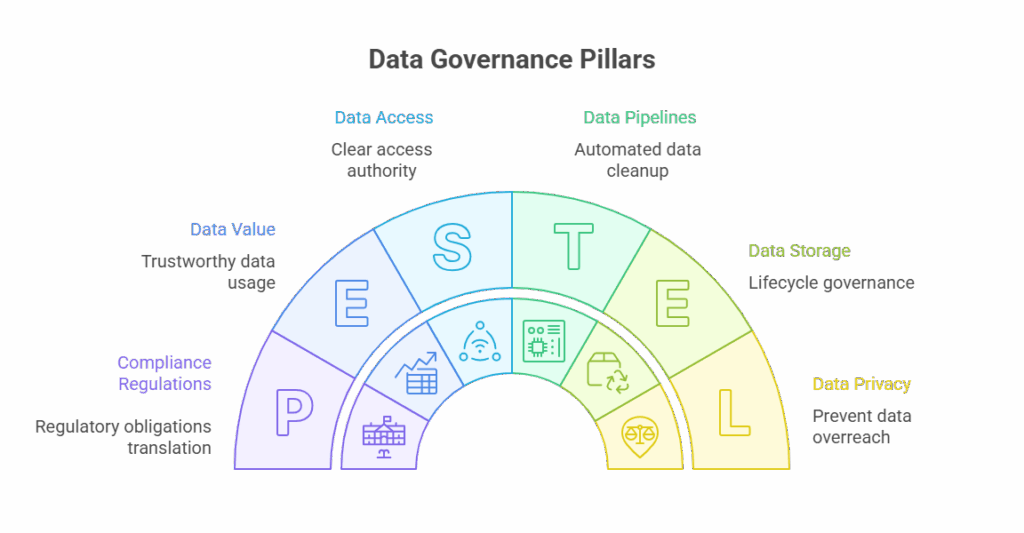
Pillars of Data Governance
If data governance does its job in your organization, it’s usually because a few fundamentals are clearly defined and consistently applied.
Data Access Policy
Who can access which data, for what reason, and for how long? This pillar is where cybersecurity best practices like least privilege and time-bound access stop becoming theory and start becoming enforceable rules.
Data Quality
When teams can’t trust the data they’re using, everything downstream suffers. Data and analytics teams define what good quality looks like. Engineering owns the pipelines and checks that stop quality from drifting over time.
Privacy and Compliance
This is a pillar that prevents accidental overreach with personal or regulated data. Compliance and legal teams define what’s allowed under regulatory and assurance frameworks like SOC 2, GDPR, or HIPAA. Security teams then make sure those boundaries are enforced wherever the data lives.
Data Lifecycle Management
Data that no longer needs to exist still carries risk. Lifecycle governance covers how data is created and how long it’s kept, as well as when it’s deleted. Data teams set retention needs. Platform and engineering teams automate the cleanup so it doesn’t need to rely on memory or good intentions.
Ownership and Stewardship
Every dataset needs a human answerable for it. Ownership makes clear who has the authority to approve access, a core principle of identity and access governance in modern data environments. It also identifies the group that carries accountability when something goes wrong. These owners often sit in data or business teams where security oversees rather than acting as the bottleneck.
Auditability and Traceability
Sooner or later, someone will ask who accessed what, and why. Auditability makes that answer straightforward instead of painful. Security and compliance depend on it for investigations and audits, while engineering ensures access activity is logged and easy to review. Audit trails should capture not just the human users, but also which non-human identity actually accessed the data.
What is data management?
Data management covers the practical, day-to-day work required to make data usable. It’s about how data is stored, moved, transformed, and kept available for the people and systems that rely on it. That includes running ETL pipelines, maintaining warehouses and lakes, managing operational databases, handling backups and recovery, and keeping metadata accurate so people can find and understand what they’re using.
Where governance defines intent, data management is about execution. It’s concerned with performance, reliability, and scale. In reality, this means making sure data arrives where it’s needed, in the right format, at the right time. Engineering and data teams own the pipelines and infrastructure, while platform and operations teams keep systems running, resilient, and cost-controlled as data volumes grow.
Importantly, data management doesn’t decide who should have access or whether a dataset should be exposed; that’s governance. Management focuses on the how, not the should.
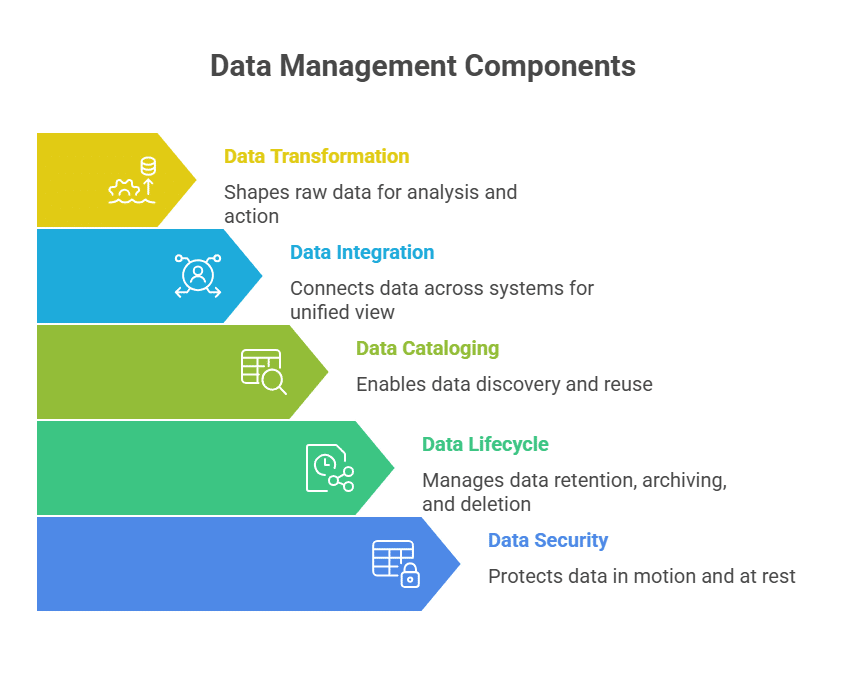
Components of Data Management
- Data storage: This is where everything lives, so analytics can run queries and teams can pull the reports they need day to day.
- Data ingestion: Pulls information from operational systems, third-party tools, and event streams, then pushes it into analytics platforms and downstream workflows.
- Data transformation: This is the cleanup and shaping step, turning raw, messy data into something analysts can work with and apps can use.
- Data integration: Connects the dots across systems so your reporting reflects reality and your apps stay consistent.
- Data cataloging and metadata management: Helps people find the right data and understand what it means, so reporting doesn’t drift into “multiple versions of the truth.”
- Data lifecycle management: All about retaining, archiving, and deleting data, balancing analytical needs, operational performance, and regulatory obligations.
- Data security operations: Supports cloud data security by protecting data in motion and at rest while keeping analytics and business operations running.
Key Differences: Data Governance vs Data Management
1. Purpose
Data governance sets the intent for how data should be used: who can access what, in which situations, and who owns the fallout if something breaks. However, data management is the “how.” It’s the hands-on work of operating the systems that store, move, and maintain data so it’s available and usable.
2. Focus Area
Governance is where risk shows up: permissions, privacy, regulatory expectations, and preventing misuse. Management is focused on operational efficiency; think pipelines, integrations, warehouses, transformations, and keeping data flowing without breaking downstream systems.
3. Ownership
Governance typically aligns with security, compliance, and legal roles, with business stakeholders also involved. On the other hand, management sits with the teams building and running the data stack day to day: data engineering, DevOps/platform, and IT operations.
4. Scope of Responsibility
Governance answers the question: Should this access exist at all, and under what constraints? Management answers: How is this data stored, transformed, and delivered once access is granted?
5. Compliance Role
Governance is where compliance gets translated into real expectations. It means mapping internal policies and external requirements like SOC 2, GDPR, HIPAA, or CCPA to access expectations. Management implements the technical pieces that support those requirements, such as encryption, retention mechanisms, and system-level controls.
6. Risk Impact
Governance reduces organizational and security risk by limiting exposure, enforcing least privilege, and supporting continuous monitoring of data access. Management reduces operational risk by improving data reliability, accuracy, uptime, and availability for teams that depend on it.
7. Tooling
Governance relies on tools for policy definition, access control, identity governance, and audit trails. Management depends on databases, ETL and orchestration tools, data warehouses, integration platforms, and master data systems.
Table 1: Key Differences
| Dimension | Data Governance | Data Management |
| Primary purpose | Defines rules, access boundaries, and accountability | Executes storage, movement, and processing of data |
| Core question | Should this data be accessed, by whom, and why? | How is this data stored, transformed, and delivered? |
| Focus | Security, compliance, privacy, risk reduction | Performance, reliability, scalability |
| Ownership | Security, compliance, legal, data governance teams | Data engineering, platform, DevOps, IT ops |
| Compliance role | Translates SOC 2, GDPR, HIPAA into enforceable policies | Implements technical controls (encryption, retention, backups) |
| Risk addressed | Overexposure, misuse, lack of auditability | Pipeline failures, stale data, downtime |
| Tooling | Policy engines, access control, identity governance, audit logs | Databases, ETL tools, warehouses, orchestration platforms |
How do data governance and data management work together?
Governance protects meaning and boundaries; basically, what the data represents, how sensitive it is, and what risks are acceptable. Management, on the other hand, protects functionality by keeping pipelines running, queries fast, backups reliable, and downstream systems fed. You need both.
Governance without strong management leads to compliant-but-unusable data. Management without strong governance produces highly available data that quietly becomes overexposed, misused, or impossible to audit once regulators, auditors, or incident responders come asking questions.
This gap matters a lot more now that data access is focused on automation. You can write all the right policies, but they won’t enforce themselves, especially when access runs through NHIs that don’t map cleanly to classic governance. In those environments, secret management is one of the quickest ways to cut down long-lived credentials and reduce blast radius. If enforcement is inconsistent, governance slowly turns into paperwork, no matter how polished the docs are.
Operationalizing Data Governance with Apono
Treating data governance and data management as the same function is where many data programs quietly fail. That risk grows as access shifts from humans to pipelines, service accounts, and agents. Policies don’t reduce exposure when enforcement relies on long-lived credentials and standing access that outlasts the task.
Apono acts as the enforcement layer between data governance and data management, translating governance decisions into time-bound, least-privilege access across both human and non-human identities, without slowing engineering teams down. By automating Just-In-Time access and maintaining centralized audit trails, Apono helps organizations operating under compliance regulations, such as HIPAA and GDPR, to turn governance from a documented intention into something measurable and defensible.
Explore this approach in practice through a live Apono walkthrough.



