Data Governance Policy: 9 Fundamental Components
The Apono Team
February 12, 2026

In 2026, you’re not just managing clusters and pipelines; you are managing the risk associated with the data flowing through them. As environments become decentralized and agentic, traditional, static data governance policies have morphed from inefficient to a security liability.
The financial stakes of data governance failures have reached an all-time high. The average cost of a data breach in the United States has reached $10.22 million. For cloud-native teams, 72% of these breaches now involve data stored in cloud environments, often spanning multiple environments where fragmented access controls create easy paths for lateral movement.
The core issue is not a lack of policy, but a lack of operationalization. Most enterprise policies are static PDFs that bear little resemblance to how engineering teams actually work. If you consider that roughly 30% of breaches now involve third-party or supply-chain compromises, and many AI-related security incidents stem from identity and access control failures, the conclusion is unavoidable. Policy must evolve from a set of suggestions in a document into a comprehensive code-driven enforcement layer.
What is a data governance policy?
A data governance policy is the foundational blueprint that defines how your organization’s information assets are managed, utilized, and protected. It establishes the internal rules and accountability models required to ensure data remains a reliable asset.
Unlike a data governance framework (which provides the structural methodology), the policy serves as the legal and operational mandate. It converts high-level strategic goals into concrete requirements for data handling, access, and auditing across the entire data lifecycle.
In practice, a data governance policy is not owned by a single team. In modern cloud environments, collaboration among data owners, security, compliance, and execs ensures that data governance extends to human users and non-human identities (NHIs), such as service accounts and autonomous agents, that access data independently. In modern cloud environments, data governance policies increasingly rely on identity governance software to enforce accountability across both humans and NHIs.
Data Governance vs Data Security vs Data Management
While data governance and data management are often used interchangeably in boardrooms, they represent distinct functional layers in the DevOps stack. In a nutshell: Management builds the pipelines, security locks the valves, and data governance decides who gets the key and why. Crucially, enforcement for all three applies equally to human users and NHIs.
Table 1: Data Governance vs Security vs Management
| Primary Focus | Objective | |
| Data Governance | Strategy & Oversight | Establishing who can do what with which data under what conditions. |
| Data Security | Protection & Defense | Implementing the technical controls (encryption, firewalls, IAM, etc) to prevent unauthorized access. |
| Data Management | Execution & Logistics | The daily architecture of ingesting, storing, and processing data for operational use. |
Why Data Governance Matters in 2026
Gone are the simple days of network perimeter security and database firewalls. Today, the primary attack surface has shifted to the identity fabric. Machine identities already outnumber human accounts and are growing rapidly year over year. The risk from ungoverned NHIs often exceeds that of a single compromised employee device, significantly expanding organizational threat exposure across cloud environments.
Regulators are highly aware of the changes introduced by the shift to the new agentic era of computing. The EU AI Act and updated NIST frameworks have moved from principle to enforceable accountability. Organizations must now prove not only that they have a policy, but that their policy is programmatically enforced. Governance is the enabler of resilient, machine-led operations, underpinning trust in data-driven decision making.
9 Fundamental Components of a Data Governance Policy
1. Purpose and Scope
A modern policy must define its boundaries to prevent governance sprawl. In decentralized environments, the scope must extend beyond traditional databases to include every S3 bucket, vector store, and API endpoint that touches sensitive data.
What it Entails:
- Asset Coverage: Defining which data types (structured vs. unstructured) fall under the policy.
- Persona Identification: Identifying every user and service account (NHI) within the ecosystem.
- Geographic Boundaries: Addressing data residency requirements for global operations.
How to Implement:
Define scope at the resource level and use automated discovery tools to continuously map new resources to the policy.
2. Roles and Responsibilities
This is the accountability layer. Without a clear human owner for every identity, you cannot verify intent or conduct a meaningful forensic audit after a breach.
What it Entails:
Assigning every service account, API key, and AI agent to a human Data Owner or Custodian responsible for its entire lifecycle.
How to Implement:
Transition to a self-service access model where owners define automated approval workflows and use Just-in-Time (JIT) provisioning to fulfill duties.
3. Data Classification and Handling Standards
Classification is the logic layer that categorizes information based on sensitivity (Public, Internal, Confidential, Restricted).
What it Entails:
- Specifying handling standards for each tier, including encryption and storage mandates.
- Ensuring classification tags can be enforced by access policies that limit NHI access to time-bounded sessions.
How to Implement:
Deploy automated discovery tools that use AI-powered data classification to apply metadata-driven labels as code, integrating them directly into access controls.
4. Data Access Policy
The data access policy defines the technical mechanisms for entry by specifying rules governing how permissions can be requested and granted. Your data access policy is your primary defense against identity debt.
What it Entails:
- The Principle of Least Privilege: Ensuring both human users and NHIs receive only the minimum access level required for a specific task.
- Approvals: Tiered workflows where routine access is automated via policy triggers, while high-risk data access requires manual authorization.
- Time-Bounded Access: Ensuring all permissions are ephemeral and expire automatically once a task is completed.
How to Implement:
Retire static, long-lived roles in favor of a JIT architecture. Inventory standing privileges and replace permanent admin rights with ephemeral, scoped credentials.
5. Data Usage Policy
The data usage policy establishes the rules of engagement by defining exactly what an identity is permitted to do with data once access to it is granted. While access addresses the entry, usage prevents scope creep and unauthorized repurposing.
What it Entails:
- Acceptable Use: Strict standards for data processing, including explicit prohibitions on using production datasets for unauthorized AI model training.
- Privacy Standards: Mandatory masking or anonymization for regulated data (GDPR/HIPAA/SOC 2) to ensure privacy-by-design during analysis.
- NHI Guardrails: Use behavioral telemetry to monitor NHIs.
How to Implement:
Link permissions to specific task windows. JIT access enforces time-bounded usage and significantly reduces post-task misuse.
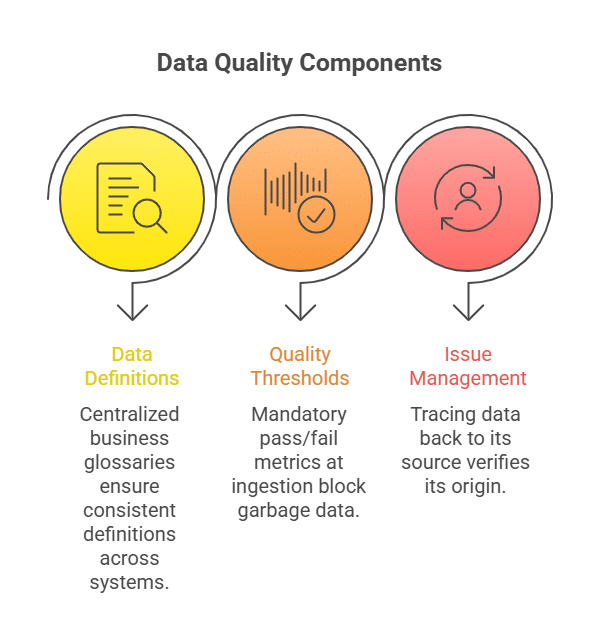
6. Data Quality Standards
Data quality standards are the technical benchmarks that ensure data is fit for purpose. Without enforceable quality controls, organizations risk scaling bad decisions faster through analytics and AI.
What it Entails:
- Data Definitions: Centralized business glossaries to ensure “Revenue” is consistently defined across analytics systems and AI models.
- Quality Thresholds: Mandatory Pass/Fail metrics at the ingestion layer to block garbage-in scenarios.
- Issue Management: Tracing data back to its source to verify its origin.
Implementation (and The Apono Edge):
Integrate data observability directly into the pipeline. Apono can support this model by granting temporary, elevated permissions when investigation or remediation is required.
7. Data Lifecycle Rules
Managing the temporal dimension of data is a strategic necessity for minimizing the liability surface. Retaining data longer than required increases breach impact and audit complexity, often without delivering any business value.
What it Entails:
- Retention: Defining legal and business limits for data storage.
- Archive Protocols: Moving “cold” data to encrypted, low-cost storage with restricted access.
- Disposal: Ensuring data is unrecoverable per NIST SP 800-88 standards.
How to Implement:
- Automate retention at the infrastructure level.
- Ensure that deletion actually means the cryptographical erasure of the keys.
8. Logging, Monitoring, and Audit Requirements
Logging and monitoring provide the uninterrupted visibility required to transform a static policy into a defensible security posture. Organizations must maintain an immutable, near real-time trail of every access decision to satisfy regulatory defensible governance requirements.
What it Entails:
- Immutable Audit Trails: Capturing the Who, What, When, and Why for every request.
- Real-time Monitoring: Automated systems must flag anomalous access patterns as they happen.
- Identity Inclusion: Audit planes must treat NHIs with special attention, capturing every machine-to-machine dialogue and AI agent action with the same rigor as human activity.
How to Implement:
- Integrate automated observability instead of periodic manual (and resource-intensive) reviews.
- Move access decisions out of ticket queues and into an identity-centric policy engine that generates audit evidence at the moment of enforcement.
9. Incident Response for Data Exposure and Misuse
Incident response is a governance function as much as a security one. It determines how quickly an organization can contain, investigate, and recover from unauthorized data exposure or misuse.
What it Entails:
- Containment Protocols: Automated immediate actions to halt data exfiltration and isolate affected systems.
- Identity Revocation: The ability to instantly terminate active sessions and revoke permissions for both human users and NHIs suspected of compromise.
- Communication Channels: Pre-defined notification trees that immediately and contextually alert Legal, DevOps, and the CISO to ensure regulatory compliance and operational alignment.
- Post-Mortem Analysis: Using lineage and logs to identify exactly what data was exposed.
How to Implement:
Establish automated revocation triggers. For example, if your EDR detects a compromise on a developer’s machine, your governance layer should automatically revoke all their JIT sessions across every cloud database.
Table 2: Components of a Data Governance Policy
| Component | What It Covers | How to Implement | |
| Purpose and Scope | Defines which data, identities (human + NHI), and regions are governed. | Scope policies at the resource level with automated discovery. | |
| Roles and Responsibilities | Assigns every identity and service account to a clear human owner. | Use self-service access with owner-defined JIT approval flows. | |
| Data Classification & Handling | Classifies data by sensitivity and enforces handling requirements. | Apply labels as code and enforce them through access controls. | |
| Data Access Policy | Controls how access is requested, approved, and expired. | Replace standing roles with ephemeral JIT permissions. | |
| Data Usage Policy | Defines what identities can do with data after access is granted. | Tie access to task-specific, time-bound sessions. | |
| Data Quality Standards | Ensures data accuracy, consistency, and traceability. | Embed data observability and grant temporary investigation access. | |
| Data Lifecycle Rules | Governs data retention, archiving, and secure deletion. | Automate retention and enforce cryptographic erasure. | |
| Logging & Auditing | Captures real-time, immutable access activity for all identities. | Generate audit logs automatically at policy enforcement time. | |
| Incident Response | Defines containment, revocation, and investigation workflows. | Trigger automatic session revocation on compromise signals. |
How Access Management Enforces Data Governance Policies
A data governance policy is only as effective as its enforcement layer. Static roles and manual approval queues create identity sprawl. For a policy to be more than a documented ideal, it must be programmatically enforced across every cloud resource and API.
Apono operationalizes data governance by transforming passive guidelines into enforceable, identity-aware controls applied consistently across cloud infrastructure, data stores, and APIs.
As a cloud-native access management platform, Apono replaces risky, long-lived permissions with Just-In-Time (JIT) access. This ensures that every identity operates under a strict Least Privilege model, receiving ephemeral, per-session credentials that expire automatically.
This shift to dynamic access directly supports key access-control requirements across SOC 2, GDPR, and HIPAA. By capturing the full context behind every access decision, Apono ensures your governance posture is defensible by default. You move away from manual audit archaeology and toward a centralized, immutable audit plane where compliance is a continuous byproduct of your operational workflow.
Data governance only works when access is continuously enforced. Explore how Apono enforces access compliance across cloud environments, turning policy into proof and making audit readiness a built-in part of how teams operate. Or, book a live demo to see JIT access in action.





